먼저, 다음과 같이 H2O DriverlessAI 설치 파일을 download 받습니다. 저는 여기서 IBM POWER8 CPU와 Pascal P100 GPU를 장착한 Minsky 서버를 사용했습니다.
[root@p57a22 data]# wget https://s3.amazonaws.com/artifacts.h2o.ai/releases/ai/h2o/dai/rel-1.3.1-12/ppc64le-centos7/dai-1.3.1-linux-ppc64le.sh

(rpm을 download 받아서 해도 됩니다만, 이게 TAR SH를 download 받는 것이 여러모로 가장 편리합니다.)
이것을 수행하면 그 directory를 DRIVERLESS_AI_HOME으로 하여 필요한 binary engine이 설치됩니다. 다른 directory에 설치하고 싶으시면 ./dai-1.3.1-linux-ppc64le.sh "설치_디렉토리_이름"과 같이 directory 이름을 직접 적어도 됩니다.
[root@p57a22 data]# chmod a+x dai-1.3.1-linux-ppc64le.sh
[root@p57a22 data]# ./dai-1.3.1-linux-ppc64le.sh
Extracting to dai-1.3.1-linux-ppc64le ...
...
Starting Driverless AI
run-dai.sh
Stopping Driverless AI
kill-dai.sh
Debugging Driverless AI
cat log/dai.out
cat log/h2o.out
cat log/procsy.out
설치된 directory로 들어가보면 start와 stop에 필요한 shell script와 함께 각종 jar 및 python 파일들이 들어있습니다. 기본적으로 H2O DriverlessAI는 python과 java로 되어 있으며, 독자적인 python engine (v3.6.1)과 jre (v1.8)을 가지고 있습니다. 물론 이것들은 산업 표준 그대로의 것들입니다.
[root@p57a22 data]# cd dai-1.3.1-linux-ppc64le
[root@p57a22 dai-1.3.1-linux-ppc64le]# ls
bin cuda-9.2 h2o.jar log README_TAR_SH.txt src
BUILD_INFO.txt dai-env.sh include mojo2-runtime.jar README.txt start-dai.sh
config.toml docs jre procsy README_WSL.txt start-h2o.sh
cpu-only h2oai_autoreport kill-dai.sh python run-dai.sh start-procsy.sh
cuda-8.0 h2oai-dai-connectors.jar lib README_DOCKER.txt sample_data VERSION.txt
cuda-9.0 h2oai_scorer LICENSE README_RPM_DEB.txt share vis-data-server.jar
dai-env.sh를 수행하면 필요한 환경 변수들이 자동 설정됩니다.
[root@p57a22 dai-1.3.1-linux-ppc64le]# ./dai-env.sh
======================================================================
DRIVERLESS_AI_HOME is /home/data/dai-1.3.1-linux-ppc64le
DRIVERLESS_AI_CONFIG_FILE is /home/data/dai-1.3.1-linux-ppc64le/config.toml
DRIVERLESS_AI_JAVA_HOME is /home/data/dai-1.3.1-linux-ppc64le/jre
JAVA_HOME is /home/data/dai-1.3.1-linux-ppc64le/jre
CUDA Version is cuda-9.2
DRIVERLESS_AI_H2O_XMX is 233580m
DRIVERLESS_AI_H2O_PORT is 54321
DRIVERLESS_AI_PROCSY_PORT is 8080
OMP_NUM_THREADS is 16
OPENBLAS_MAIN_FREE is 1
LANG is en_US.UTF-8
MAGIC is /home/data/dai-1.3.1-linux-ppc64le/share/misc/magic
HOME is /root
uid=0(root) gid=0(root) groups=0(root),2001(powerai)
======================================================================
이제 run-dai.sh를 수행하면 H2O DAI가 시작됩니다.
[root@p57a22 dai-1.3.1-linux-ppc64le]# ./run-dai.sh
======================================================================
DRIVERLESS_AI_HOME is /home/data/dai-1.3.1-linux-ppc64le
DRIVERLESS_AI_CONFIG_FILE is /home/data/dai-1.3.1-linux-ppc64le/config.toml
DRIVERLESS_AI_JAVA_HOME is /home/data/dai-1.3.1-linux-ppc64le/jre
JAVA_HOME is /home/data/dai-1.3.1-linux-ppc64le/jre
CUDA Version is cuda-9.2
DRIVERLESS_AI_H2O_XMX is 233580m
DRIVERLESS_AI_H2O_PORT is 54321
DRIVERLESS_AI_PROCSY_PORT is 8080
OMP_NUM_THREADS is 16
OPENBLAS_MAIN_FREE is 1
LANG is en_US.UTF-8
MAGIC is /home/data/dai-1.3.1-linux-ppc64le/share/misc/magic
HOME is /root
uid=0(root) gid=0(root) groups=0(root),2001(powerai)
======================================================================
Started.
이후에는 http://129.40.XX.XX:12345 와 같이 12345 포트로 web browser를 통해 dataset을 import하고 training (H2O에서는 experiment라고 합니다)을 하면 됩니다.
(아래 그림에 나오는 IP address는 VPN으로만 접근 가능한 주소이니 공연히 두들겨 보지 마십시요... 시간낭비입니다 ㅋ)

맨 처음 나오는 나오는 화면은 login 화면인데, 여기서의 user id와 passwd는 임의로 직접 여기서 정하시면 됩니다. 이 user id는 OS의 user id가 아니라, 그냥 DriverlessAI의 user id입니다. 이 user id는 login 했을 때 내가 볼 수 있는 dataset과 train된 model들 등을 구분하기 위한 것이며, 또한 H2O DAI의 license의 단위가 됩니다. DAI의 license는 CPU core나 server box 수가 아니라 user 단위로 됩니다.
Login 이후에는 dataset부터 import 하게 되어 있습니다. PC에서 upload하셔도 되고, 미리 서버에 upload해둔 file을 서버의 filesystem에서 가져와도 됩니다. 모든 CSV 포맷 파일을 그대로 사용하실 수 있습니다. Excel 파일이 있다면 그건 수작업으로 CSV 포맷으로 저장하셔서 사용하셔야 합니다. 여기서는 https://timeseries.weebly.com/data-sets.html 에서 얻은 각 숙박시설의 점유율 data를 가지고 해보겠습니다. 이는 달별로 호텔, 모텔, 야영장, 배낭족 등의 점유율을 정리한 100여줄의 매우 작은 자료입니다.


Dataset이 import되면 즉각 자동으로 각 column들의 Min/Max/Avg/Dev 등을 계산해주는 것은 물론, 다양한 형태로 visualize까지 할 수 있습니다. 가령 아래 그림은 각 column 간의 상관관계를 보여주는 도표입니다.



이제 predict 메뉴를 눌러 이 dataset으로 model을 training하겠습니다.

여기서 지정해줄 것은 사실상 딱 하나, 어떤 column에 대해서 향후 예측을 하고 싶으냐만 정하시면 됩니다. 여기서는 Holiday Park Occupancy Rate라는 칼럼으로 하겠습니다.


나머지는 옵션들입니다. 가령 이 spreadsheet의 칼럼 중 시간 부분이 있다면 그걸 Time 칼럼으로 지정하시는 것이 좋습니다. Time 칼럼을 Auto로 놓으면 아예 자동으로 어떤 칼럼이 시간 부분인지 탐지하여 설정합니다.

그리고 조종할 부분은 3개의 라디오 다이얼 같은 것 뿐입니다. 왼쪽부터 Accuracy (정확도), Time (시간), Interpretability (기계학습 해석) 다이얼인데, 1~10까지의 '강약'을 조절하는 방식으로 되어 있습니다. 가령 Accuracy를 높일 경우 사용되는 알고리즘이 GLM과 XGBoost에서 XGBoost로 바뀐다든지, Time을 늘릴 경우 training 반복 회수가 12번에서 523번으로 바뀐다든지 하는 식입니다. 어려운 세부 튜닝을 자동으로 해주므로 우리는 그냥 보고서 제출 때까지 시간 여유가 얼마나 있는지 등만 결정하면 되는 것입니다.


물론 아래와 같이 expert setting을 할 수도 있습니다. Tensorflow라든가 RuleFit 같은 것들은 현재 alpha 버전으로 제공됩니다.

Training을 시작하면 왼쪽 아래에는 validation, 즉 기본적으로 RMSE (Root Mean Square Error)가 display되면서 error가 점차 줄어드는 것을 보실 수 있습니다. 오른쪽 아래에는 data 내의 실제 값과, training 회수가 반복되면서 prediction하는 값의 상관 관계가 그래프로 보여집니다. 처음에는 저 그래프는 분산도가 크게 보여지다가, training이 잘 되면 점차 직선으로 수렴되는 것을 보실 수 있습니다. 또한 중앙 상단의 모델 완성%를 보여주는 계기판 위에는 "3912개의 feature에 대해 896개 모델 중 118개에 대해 평가를 완료"라는 메시지가 보이는데, 이 숫자들은 training이 진행되면서 최적화를 거쳐 계속 동적으로 변화됩니다.

H2O DAI에서는 필요에 따라 띄엄띄엄 GPU를 사용합니다. 다음과 같이 nvidia-smi로도 그 사용 모습을 모니터링할 수 있고, 또 오른쪽 하단의 'GPU usage' tab을 클릭하면 GPU 사용률을 GPU별로 볼 수 있습니다.
Fri Oct 5 00:51:19 2018
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 396.26 Driver Version: 396.26 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 Tesla P100-SXM2... On | 00000002:01:00.0 Off | 0 |
| N/A 31C P0 39W / 300W | 600MiB / 16280MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
| 1 Tesla P100-SXM2... On | 00000003:01:00.0 Off | 0 |
| N/A 33C P0 42W / 300W | 608MiB / 16280MiB | 35% Default |
+-------------------------------+----------------------+----------------------+
| 2 Tesla P100-SXM2... On | 0000000A:01:00.0 Off | 0 |
| N/A 30C P0 38W / 300W | 604MiB / 16280MiB | 20% Default |
+-------------------------------+----------------------+----------------------+
| 3 Tesla P100-SXM2... On | 0000000B:01:00.0 Off | 0 |
| N/A 33C P0 29W / 300W | 10MiB / 16280MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
| 0 18750 C ...uild_cv_model_subprocess-end(prot=True) 295MiB |
| 0 18969 C ...uild_cv_model_subprocess-end(prot=True) 295MiB |
| 1 18749 C ...uild_cv_model_subprocess-end(prot=True) 295MiB |
| 1 18970 C ...el-running(prot=False)-XGBoostModel-fit 303MiB |
| 2 18748 C ...uild_cv_model_subprocess-end(prot=True) 295MiB |
| 2 18971 C ...ng(prot=False)-RuleFitModel-fit_glm-fit 299MiB |
+-----------------------------------------------------------------------------+

Training(DAI에서는 Experiment라고 함)이 끝나면 다음과 같이 당장 prediction을 할 수 있는 "Score on another dataset"이라는 메뉴가 제공됩니다. 여기에 training시킨 dataset과 같은 명칭과 종류의 column과 data를 가진 test dataset을 넣으면 아까 정한 target column에 대해 prediction을 해줍니다. 저는 여기에 미리 따로 잘라서 준비해둔 occupancy test dataset을 입력해보았습니다. 그 결과로 다음과 같이 해당 column에 대한 예측값을 CSV로 download 받을 수 있습니다.
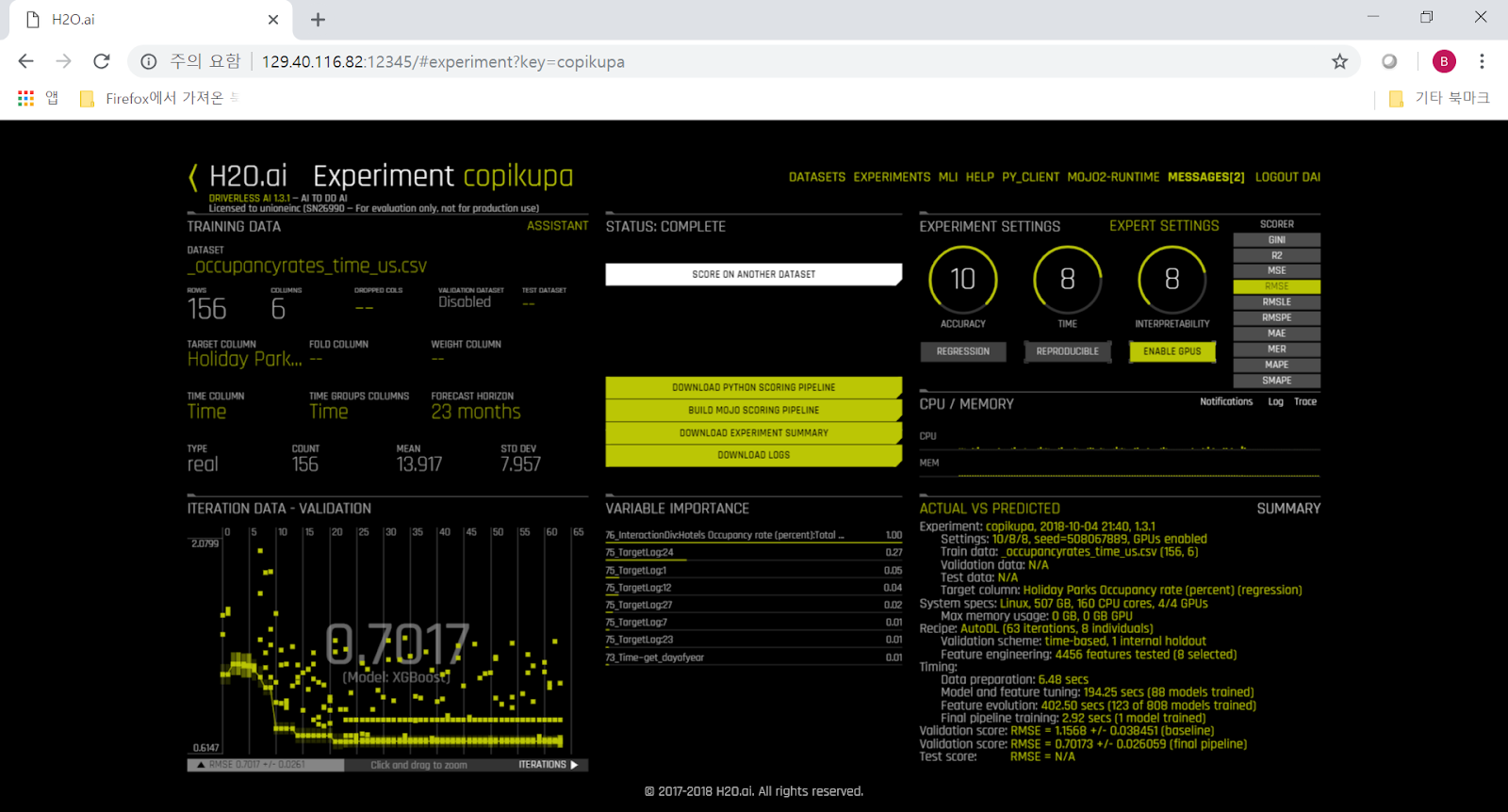


이 값을 실제 수치와 비교를 해보면 대략 다음과 같이 나옵니다. 100여줄 정도의 data로 10여분 training한 것치고는 괜찮은 예측치입니다.

또한, 이런 예측을 이렇게 DAI 서버의 web interface 말고, 여기서 train된 모델을 다른 서버로 옮겨서 python 혹은 java client program을 거쳐서 수행할 수도 있습니다. 이에 대해서는 다른 posting에서 다루겠습니다.
댓글 없음:
댓글 쓰기