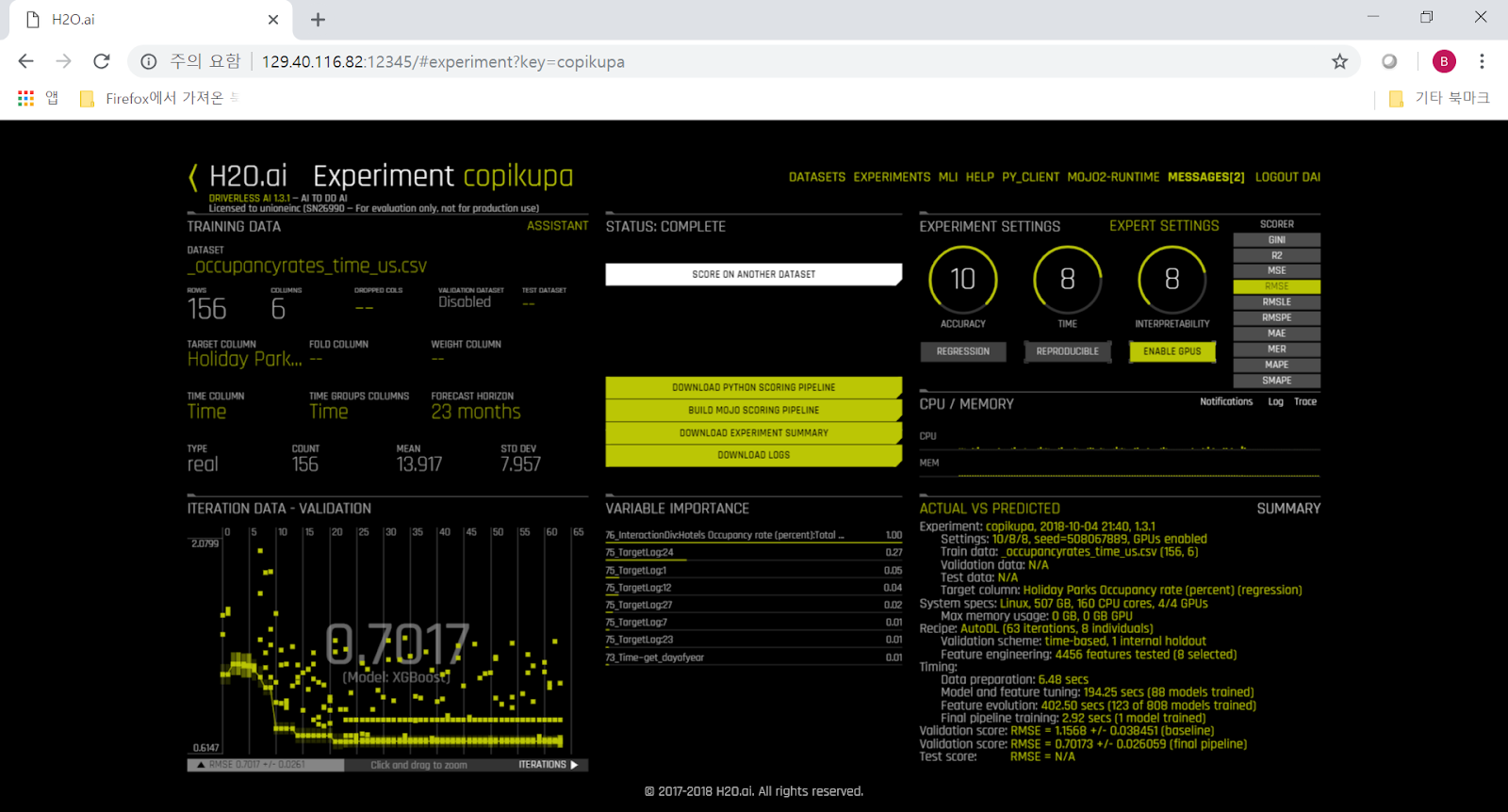
H2O DAI는 training한 모델을 이용하는 client program을 python 혹은 MOJO(java) 형태로 제공해줍니다. 먼저번 posting에서 train된 모델에 대한 python client program을 download 받기 위해서는 "Download python scoring pipeline"이라는 메뉴를 click하면 됩니다. scoring.zip이라는 zip 파일을 web browser로 download 받을 수 있습니다.
서버 상에서는 이 파일은 다음과 같이 임시 directory에 생성되어 있으니 그걸 download 받아서 사용해도 됩니다.
[root@p57a22 dai-1.3.1-linux-ppc64le]# ls -l ./tmp/h2oai_experiment_copikupa/scoring_pipeline/scorer.zip
-rw-rw----+ 1 root root 95622433 Oct 4 21:40 ./tmp/h2oai_experiment_copikupa/scoring_pipeline/scorer.zip
[root@p57a22 dai-1.3.1-linux-ppc64le]# cp ./tmp/h2oai_experiment_copikupa/scoring_pipeline/scorer.zip /home/data
이것의 압축을 풀면 다음과 같이 train된 model을 포함하는 wheel 파일과 함께, python client program을 구성하는 python code 및 shell program들이 들어 있습니다.
[root@p57a22 data]# unzip scorer.zip
Archive: scorer.zip
creating: scoring-pipeline/
inflating: scoring-pipeline/scoring.thrift
inflating: scoring-pipeline/requirements.txt
inflating: scoring-pipeline/environment.yml
inflating: scoring-pipeline/example.py
inflating: scoring-pipeline/http_server.py
inflating: scoring-pipeline/tcp_server.py
inflating: scoring-pipeline/example_client.py
inflating: scoring-pipeline/run_http_client.sh
inflating: scoring-pipeline/datatable-0.6.0.dev252-cp36-cp36m-linux_ppc64le.whl
inflating: scoring-pipeline/h2o4gpu-0.2.0.9999%2Bmaster.129ef59-cp36-cp36m-linux_ppc64le.whl
inflating: scoring-pipeline/h2oaicore-1.3.1-cp36-cp36m-linux_ppc64le.whl
inflating: scoring-pipeline/README.txt
inflating: scoring-pipeline/run_example.sh
extracting: scoring-pipeline/tcp_server_requirements.txt
extracting: scoring-pipeline/http_server_requirements.txt
inflating: scoring-pipeline/run_tcp_server.sh
inflating: scoring-pipeline/run_http_server.sh
extracting: scoring-pipeline/client_requirements.txt
inflating: scoring-pipeline/run_tcp_client.sh
inflating: scoring-pipeline/thrift_post_processing.py
inflating: scoring-pipeline/common-functions.sh
inflating: scoring-pipeline/scoring_h2oai_experiment_copikupa-1.0.0-py3-none-any.whl
extracting: scoring-pipeline/h2oai_experiment_summary_copikupa.zip
이 파일들을 다른 서버로 옮겼다고 가정하시지요. 이건 training이 아니라 train된 model을 이용한 prediction (또는 inferencing)이니까, 굳이 GPU가 달려있지 않은 일반 서버로도 충분합니다.
먼저 해당 서버에도 먼저번 posting과 같이, DAI의 TAR SH 파일을 download 받아 설치합니다.
[root@p57a22 data]# wget https://s3.amazonaws.com/artifacts.h2o.ai/releases/ai/h2o/dai/rel-1.3.1-12/ppc64le-centos7/dai-1.3.1-linux-ppc64le.sh
이것을 수행하면 그 directory를 DRIVERLESS_AI_HOME으로 하여 필요한 binary engine이 설치됩니다. 다른 directory에 설치하고 싶으시면 다음과 같이 설치하고자 하는 directory 이름을 직접 적어도 됩니다.
[root@p57a22 data]# ./dai-1.3.1-linux-ppc64le.sh /usr/local/dai-1.3.1-linux-ppc64le
설치된 directory로 들어가보면 start와 stop에 필요한 shell script와 함께 각종 jar 및 python 파일들이 들어있습니다. 기본적으로 H2O DriverlessAI는 python과 java로 되어 있으며, 독자적인 python engine (v3.6.1)과 jre (v1.8)을 가지고 있습니다. 물론 이것들은 산업 표준 그대로의 것들입니다.
[root@p57a22 data]# cd /usr/local/dai-1.3.1-linux-ppc64le
[root@p57a22 dai-1.3.1-linux-ppc64le]# ls
bin cuda-9.2 h2o.jar log README_TAR_SH.txt src
BUILD_INFO.txt dai-env.sh include mojo2-runtime.jar README.txt start-dai.sh
config.toml docs jre procsy README_WSL.txt start-h2o.sh
cpu-only h2oai_autoreport kill-dai.sh python run-dai.sh start-procsy.sh
cuda-8.0 h2oai-dai-connectors.jar lib README_DOCKER.txt sample_data VERSION.txt
cuda-9.0 h2oai_scorer LICENSE README_RPM_DEB.txt share vis-data-server.jar
dai-env.sh를 수행하면 필요한 환경 변수들이 자동 설정됩니다.
[root@p57a22 dai-1.3.1-linux-ppc64le]# ./dai-env.sh
======================================================================
DRIVERLESS_AI_HOME is /usr/local/dai-1.3.1-linux-ppc64le
DRIVERLESS_AI_CONFIG_FILE is /usr/local/dai-1.3.1-linux-ppc64le/config.toml
DRIVERLESS_AI_JAVA_HOME is /usr/localdai-1.3.1-linux-ppc64le/jre
JAVA_HOME is /usr/local/dai-1.3.1-linux-ppc64le/jre
CUDA Version is cuda-9.2
DRIVERLESS_AI_H2O_XMX is 233580m
DRIVERLESS_AI_H2O_PORT is 54321
DRIVERLESS_AI_PROCSY_PORT is 8080
OMP_NUM_THREADS is 16
OPENBLAS_MAIN_FREE is 1
LANG is en_US.UTF-8
MAGIC is /usr/local/dai-1.3.1-linux-ppc64le/share/misc/magic
HOME is /root
uid=0(root) gid=0(root) groups=0(root),2001(powerai)
======================================================================
확실히 하기 위해 PATH를 분명히 다시 export하고, 새로 설치한 DriverlessAI engine의 python을 쓰는 것인지 확인합니다.
[root@p57a22 dai-1.3.1-linux-ppc64le]# export PATH=/usr/local/dai-1.3.1-linux-ppc64le/python/bin:$PATH
[root@p57a22 dai-1.3.1-linux-ppc64le]# export PYTHONPATH=/usr/local/dai-1.3.1-linux-ppc64le/lib/python3.6/site-packages
[root@p57a22 dai-1.3.1-linux-ppc64le]# which pip
/usr/local/dai-1.3.1-linux-ppc64le/python/bin/pip
이제 pip 명령으로 보면 이 DAI의 PYTHONPATH에 pyarrow 등 필요 package들이 이미 설치가 된 것을 보실 수 있습니다.
[root@p57a22 dai-1.3.1-linux-ppc64le]# pip list | grep pyarrow
pyarrow (0.9.0)
이제 남은 것은 아까 train된 모델을 담은 wheel 파일을 pip로 설치하는 것입니다.
[root@p57a22 scoring-pipeline]# pip install /home/data/scoring-pipeline/scoring_h2oai_experiment_copikupa-1.0.0-py3-none-any.whl
Processing ./scoring_h2oai_experiment_copikupa-1.0.0-py3-none-any.whl
Installing collected packages: scoring-h2oai-experiment-copikupa
Successfully installed scoring-h2oai-experiment-copikupa-1.0.0
이제 다음과 같이 H2O DAI의 license를 export 해주고 환경변수 SCORING_PIPELINE_INSTALL_DEPENDENCIES를 0으로 export 해줍니다.
[root@p57a22 dai-1.3.1-linux-ppc64le]# export DRIVERLESS_AI_LICENSE_KEY="ZEL-GSl7nd0...MDE4LzEwLzIyCg=="
[root@p57a22 dai-1.3.1-linux-ppc64le]# export SCORING_PIPELINE_INSTALL_DEPENDENCIES=0
이제 환경변수 설정을 해주는 dai-env.sh와 함께 run_example.sh을 수행해보면 다음과 같이 나옵니다.
[root@p57a22 dai-1.3.1-linux-ppc64le]# ./dai-env.sh /home/data/scoring-pipeline/run_example.sh
======================================================================
DRIVERLESS_AI_HOME is /usr/local/dai-1.3.1-linux-ppc64le
DRIVERLESS_AI_CONFIG_FILE is /usr/local/dai-1.3.1-linux-ppc64le/config.toml
DRIVERLESS_AI_JAVA_HOME is /usr/local/dai-1.3.1-linux-ppc64le/jre
JAVA_HOME is /usr/local/dai-1.3.1-linux-ppc64le/jre
CUDA Version is cuda-9.2
DRIVERLESS_AI_H2O_XMX is 233580m
DRIVERLESS_AI_H2O_PORT is 54321
DRIVERLESS_AI_PROCSY_PORT is 8080
OMP_NUM_THREADS is 16
OPENBLAS_MAIN_FREE is 1
LANG is en_US.UTF-8
MAGIC is /home/data/dai-1.3.1-linux-ppc64le/share/misc/magic
HOME is /root
uid=0(root) gid=0(root) groups=0(root),2001(powerai)
======================================================================
Creating virtual environment...
...
---------- Score Row ----------
[7.788316249847412]
[7.006689071655273]
[21.045005798339844]
[21.044675827026367]
[11.887664794921875]
---------- Score Frame ----------
Holiday Parks Occupancy rate (percent)
0 7.788316
1 7.006689
2 21.045006
3 21.044676
4 11.887665
5 8.289392
6 9.870693
7 20.901302
8 6.830247
9 34.114899
---------- Get Per-Feature Prediction Contributions for Row ----------
[[-2.5961287021636963, -0.6367928981781006, -2.0373380184173584, -0.0076079904101789, 0.012887582182884216, 0.0021535237319767475, -0.6188143491744995, 0.0005846393178217113, 13.669371604919434]]
---------- Get Per-Feature Prediction Contributions for Frame ----------
contrib_0_Time~get_dayofyear contrib_1_TargetLag:1 contrib_1_TargetLag:7 \
0 -2.596129 -0.636793 -2.037338
1 -2.503755 -2.222152 -2.128783
2 -2.007713 5.645916 2.868525
3 5.954381 -1.163898 2.224814
4 -2.241865 -2.073594 3.084045
5 -1.311869 -2.307918 -2.090618
6 -0.312522 -1.869532 -1.919978
7 -2.004388 5.625261 2.855450
8 -2.512271 -1.851307 -2.055076
9 12.943974 4.565596 2.292724
contrib_1_TargetLag:12 contrib_1_TargetLag:23 contrib_1_TargetLag:24 \
0 -0.007608 0.012888 0.002154
1 0.049226 0.012719 0.005904
2 0.035909 0.052717 0.010889
3 -0.005368 -0.058491 0.007430
4 0.097049 0.017581 0.005795
5 0.044280 0.019071 0.007741
6 -0.006849 0.017562 0.007540
7 -0.008142 -0.006090 -0.003598
8 -0.012190 0.012719 0.003869
9 -0.007709 -0.006148 -0.027283
contrib_1_TargetLag:27 \
0 -0.618814
1 0.145105
2 0.768746
3 0.415227
4 -0.665447
5 0.258045
6 0.282250
7 0.779280
8 -0.426931
9 0.690188
contrib_2_InteractionDiv:Hotels Occupancy rate (percent):Total Occupancy rate (percent) \
0 0.000585
1 -0.020946
2 0.000645
3 0.001209
4 -0.005272
5 0.001292
6 0.002849
7 -0.005841
8 0.002059
9 -0.005811
contrib_bias
0 13.669372
1 13.669372
2 13.669372
3 13.669372
4 13.669372
5 13.669372
6 13.669372
7 13.669372
8 13.669372
9 13.669372
---------- Transform Frames ----------
---------- Retrieve column names ----------
('Time', 'Total Occupancy rate (percent)', 'Hotels Occupancy rate (percent)')
---------- Retrieve transformed column names ----------
['0_Time~get_dayofyear', '1_TargetLag:1', '1_TargetLag:7', '1_TargetLag:12', '1_TargetLag:23', '1_TargetLag:24', '1_TargetLag:27', '2_InteractionDiv:Hotels Occupancy rate (percent):Total Occupancy rate (percent)']
똑같은 일을 해주는 것이지만, 이걸 TCP server / client 형태로 구현해놓은 shell script도 있습니다. 먼저 아래와 같이 run_tcp_server.sh를 수행해주고...
[root@p57a22 dai-1.3.1-linux-ppc64le]# ./dai-env.sh /home/data/scoring-pipeline/run_tcp_server.sh
======================================================================
DRIVERLESS_AI_HOME is /usr/local/dai-1.3.1-linux-ppc64le
DRIVERLESS_AI_CONFIG_FILE is /usr/local/dai-1.3.1-linux-ppc64le/config.toml
DRIVERLESS_AI_JAVA_HOME is /usr/local/dai-1.3.1-linux-ppc64le/jre
JAVA_HOME is /usr/local/dai-1.3.1-linux-ppc64le/jre
CUDA Version is cuda-9.2
DRIVERLESS_AI_H2O_XMX is 233580m
DRIVERLESS_AI_H2O_PORT is 54321
DRIVERLESS_AI_PROCSY_PORT is 8080
OMP_NUM_THREADS is 16
OPENBLAS_MAIN_FREE is 1
LANG is en_US.UTF-8
MAGIC is /usr/local/dai-1.3.1-linux-ppc64le/share/misc/magic
HOME is /root
uid=0(root) gid=0(root) groups=0(root),2001(powerai)
==========================================================
...
TCP scoring service listening on port 9090...
이 상태에서 다른 terminal에서 run_tcp_client.sh를 수행해주면 다음과 같이 나옵니다.
[root@p57a22 dai-1.3.1-linux-ppc64le]# ./dai-env.sh /home/data/scoring-pipeline/run_tcp_client.sh
======================================================================
DRIVERLESS_AI_HOME is /usr/local/dai-1.3.1-linux-ppc64le
DRIVERLESS_AI_CONFIG_FILE is /usr/local/dai-1.3.1-linux-ppc64le/config.toml
DRIVERLESS_AI_JAVA_HOME is /usr/local/dai-1.3.1-linux-ppc64le/jre
JAVA_HOME is /usr/local/dai-1.3.1-linux-ppc64le/jre
CUDA Version is cuda-9.2
DRIVERLESS_AI_H2O_XMX is 233580m
DRIVERLESS_AI_H2O_PORT is 54321
DRIVERLESS_AI_PROCSY_PORT is 8080
OMP_NUM_THREADS is 16
OPENBLAS_MAIN_FREE is 1
LANG is en_US.UTF-8
MAGIC is /usr/local/dai-1.3.1-linux-ppc64le/share/misc/magic
HOME is /root
uid=0(root) gid=0(root) groups=0(root),2001(powerai)
======================================================================
Scoring server hash:
Scoring individual rows...
[7.788316249847412]
[7.006689071655273]
[21.045005798339844]
[21.044675827026367]
[11.887664794921875]
Scoring multiple rows...
[[7.788316249847412], [7.006689071655273], [21.045005798339844], [21.044675827026367], [11.887664794921875]]
Retrieve column names
['Time', 'Total Occupancy rate (percent)', 'Hotels Occupancy rate (percent)']
Retrieve transformed column names
['0_Time~get_dayofyear', '1_TargetLag:1', '1_TargetLag:7', '1_TargetLag:12', '1_TargetLag:23', '1_TargetLag:24', '1_TargetLag:27', '2_InteractionDiv:Hotels Occupancy rate (percent):Total Occupancy rate (percent)']