https://github.com/NVIDIA/DIGITS/blob/master/docs/GettingStarted.md
DIGITS는 NVIDIA에서 내놓은 오픈소스 기반의 딥 러닝 toolkit입니다. DIGITS에 대해서 NVIDIA가 소개해놓은 글 ( https://developer.nvidia.com/digits )을 읽어보면 대체 이게 뭐라는 것인지 명확하지는 않습니다. 아래와 같이 그냥 좋은 말만 나와 있거든요. 사실 이런 경향은 IBM을 포함한 모든 벤더들이 다 보여주고 있습니다.
The NVIDIA Deep Learning GPU Training System (DIGITS) puts the power of deep learning into the hands of engineers and data scientists. DIGITS can be used to rapidly train the highly accurate deep neural network (DNNs) for image classification, segmentation and object detection tasks.
결론적으로, DIGITS는 caffe나 torch와 같은 딥 러닝용 framework 자체는 아니고, caffe나 torch를 이용하여 딥 러닝을 수행할 때 좀 더 쉽고 빠르게 할 수 있게 해주는 유용한 웹 기반의 tool입니다. 아마 당장 나오는 질문이 '그럼 tensorflow는 안 되나요'라는 것일텐데, 2017년 7월 24일 현재 당장은 안 됩니다. 그러나 NVIDIA도 DIGITS에 tensorflow 지원을 추가하려고 하고 있고, 이번 달에 나온다고 합니다.
여기서는 caffe를 이용해서 가장 간단한 딥 러닝 training인 MNIST dataset에 대한 LeNet 신경망 training을 DIGITS를 통해 해보도록 하겠습니다.
nvidia-caffe와 digits의 설치는 IBM PowerAI toolkit에서 제공되는 것을 그대로 사용하겠습니다. 그 설치 방법에 대해서는 지난번 posting ( http://hwengineer.blogspot.kr/2017/05/minsky-cuda-powerai-tuning.html )을 참조하시기 바랍니다.
먼저, 그냥 caffe를 이용하여 MNIST dataset에 대한 LeNet 신경망 training을 하는 방법을 봐야 하는데, 이에 대해서는 역시 지난번 posting ( http://hwengineer.blogspot.kr/2017/06/mnist-gpu-cpu-deep-learning.html )에 잘 나와 있으니 그를 참조하시기 바랍니다.
오늘 사례는 GPU가 없는 환경에서 digits를 수행해야 합니다.
시작하기 전에 DIGITS 관련 환경변수를 setup해야 합니다. DIGITS는 위에서 언급한 것처럼 caffe와 torch를 사용하는 것이기 때문에, "apt-get install digits" 명령만 내려도 자동으로 caffe-nv와 torch를 함께 설치합니다. 마찬가지로, DIGITS를 사용하기 위해 PowerAI에서 제공하는 환경변수 setup script인 /opt/DL/digits/bin/digits-activate를 수행해도, caffe-nv와 torch 관련 환경변수들이 함께 setup 됩니다. 먼저 기본 상태의 PATH 관련 환경 변수를 확인하겠습니다.
u0017496@sys-88165:~$ env | grep PATH
PATH=/home/u0017496/bin:/home/u0017496/.local/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin
이제 PowerAI에서 제공하는 환경변수 setup script인 /opt/DL/digits/bin/digits-activate를 수행하겠습니다. 앞에 sh 또는 .을 함께 입력하셔야 한다는 것에 유의하십시요.
u0017496@sys-88165:~$ . /opt/DL/digits/bin/digits-activate
이제 다시 환경변수를 확인하면, openblas와 nccl, cuda 등은 물론이고, torch를 위한 LUA 관련 PATH들도 자동 설정된 것을 보실 수 있습니다.
u0017496@sys-88165:~$ env | grep PATH
LD_LIBRARY_PATH=/opt/DL/openblas/lib:/opt/DL/nccl/lib:/opt/DL/caffe-nv/lib:/usr/local/cuda-8.0/lib64:/opt/DL/torch/lib:/opt/DL/torch/lib/lua/5.1
PATH=/home/u0017496/bin:/home/u0017496/.local/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/opt/DL/caffe-nv/bin:/opt/DL/torch/bin:/opt/DL/digits
LUA_PATH=/home/u0017496/.luarocks/share/lua/5.1/?.lua;/home/u0017496/.luarocks/share/lua/5.1/?/init.lua;/opt/DL/torch/share/lua/5.1/?.lua;/opt/DL/torch/share/lua/5.1/?/init.lua;
LUA_CPATH=/home/u0017496/.luarocks/lib/lua/5.1/?.so;/opt/DL/torch/lib/lua/5.1/?.so;
DYLD_LIBRARY_PATH=/opt/DL/torch/lib:/opt/DL/torch/lib/lua/5.1
PYTHONPATH=/opt/DL/caffe-nv/python:/opt/DL/digits
이제 python을 이용하여 홈 디렉토리 밑에 mnist dataset을 download 받겠습니다. 이때 digits의 download_data 모듈을 유용하게 사용할 수 있습니다.
u0017496@sys-88165:~$ python -m digits.download_data mnist ~/mnist
Downloading url=http://yann.lecun.com/exdb/mnist/train-images-idx3-ubyte.gz ...
Downloading url=http://yann.lecun.com/exdb/mnist/train-labels-idx1-ubyte.gz ...
Downloading url=http://yann.lecun.com/exdb/mnist/t10k-images-idx3-ubyte.gz ...
Downloading url=http://yann.lecun.com/exdb/mnist/t10k-labels-idx1-ubyte.gz ...
Uncompressing file=train-images-idx3-ubyte.gz ...
Uncompressing file=train-labels-idx1-ubyte.gz ...
Uncompressing file=t10k-images-idx3-ubyte.gz ...
Uncompressing file=t10k-labels-idx1-ubyte.gz ...
Reading labels from /home/u0017496/mnist/train-labels.bin ...
Reading images from /home/u0017496/mnist/train-images.bin ...
Reading labels from /home/u0017496/mnist/test-labels.bin ...
Reading images from /home/u0017496/mnist/test-images.bin ...
Dataset directory is created successfully at '/home/u0017496/mnist'
Done after 24.0719361305 seconds.
이 python 명령 한줄이면 mnist dataset이 모두 자동으로 다 준비된 것입니다. 아래에서 보시다시피 ~/mnist/train 밑에 train data가 들어가 있는 것을 확인하실 수 있습니다. ~/mnist/test 밑의 data는 이름과는 달리 test가 아니라 validation을 위해 사용될 것입니다.
u0017496@sys-88165:~$ cd mnist
u0017496@sys-88165:~/mnist$ pwd
/home/u0017496/mnist
u0017496@sys-88165:~/mnist$ ls
t10k-images-idx3-ubyte.gz test-images.bin train-images.bin train-labels-idx1-ubyte.gz
t10k-labels-idx1-ubyte.gz test-labels.bin train-images-idx3-ubyte.gz
test train train-labels.bin
u0017496@sys-88165:~/mnist$ cd train
u0017496@sys-88165:~/mnist/train$ ls
0 1 2 3 4 5 6 7 8 9 labels.txt train.txt
이제 digits-server를 수행합니다. 이는 shell cript로 되어 있으며, daemon화 되어 있지는 않으므로 nohup ~ & 구문을 써서 구동하시는 것이 좋습니다.
u0017496@sys-88165:~$ /opt/DL/digits/digits-devserver &
___ ___ ___ ___ _____ ___
| \_ _/ __|_ _|_ _/ __|
| |) | | (_ || | | | \__ \
|___/___\___|___| |_| |___/ 5.0.0
/usr/lib/python2.7/dist-packages/matplotlib/font_manager.py:273: UserWarning: Matplotlib is building the font cache using fc-list. This may take a moment.
warnings.warn('Matplotlib is building the font cache using fc-list. This may take a moment.')
NVIDIA: no NVIDIA devices found
cudaRuntimeGetVersion() failed with error #30
2017-07-20 02:33:14 [INFO ] Loaded 0 jobs.
위에서 보시다시피 no NVIDIA devices found라고 error/warning이 있습니다만, 이는 제가 쓰는 이 시스템에 GPU가 없어서 그런 것이니 일단 무시하십시요.
이제 웹 브라우저를 이용해서 http://서버IP주소:5000/ 로 접속하십시요. 그러면 아래와 같이 'Models'라는 메뉴 화면에 접속하게 됩니다.

여기서 아래와 같이 Datasets > New Dataset > Images > Classification 순으로 click 하면 login page로 접속하게 됩니다. 사용자 id를 넣으라고 나올텐데, 이는 사용하시는 OS user명을 넣으시면 됩니다.


이제 아래와 같은 New Image Classification Dataset 메뉴에 들어왔습니다. 여기서 training images에는 위에서 보신 mnist train 디렉토리를 아래와 같이 입력하시고, image type은 Grayscale로, image size는 28 x 28로 변경하십시요. 또 'separate images validation folder'에 check 표시를 클릭해주시면 추가 메뉴가 나오는데, 거기에는 위에서 언급한 대로 mnist test 디렉토리를 입력해주시면 됩니다. Backend DB는 LMDB로 지정하시고, dataset 이름을 적절한 것으로 지정하십시요. 여기서는 MNIST로 정하겠습니다.


그리고나서 이제 바닥의 파란색 Create 버튼을 click하시면 됩니다. 그러면 우측 상태 메뉴에서 Job Status가 running으로 나오는 것을 보실 수 있습니다. 아래 그림에서는 'Create DB (train)'이 현재 8% 진행되었고 전체적으로는 5분 34초 걸릴 것이라고 예상되어 있는 것을 보실 수 있습니다. 여기서 DB라 함은 LMDB를 말하는 것입니다. LMDB는 Lightning Memory – Mapped Database라는 것으로서, 간단히 말하면 jpeg 등의 작은 파일로 된 data들을 담는 key-value store이며, 일반 DBMS는 아니지만 고속의 성능을 내기 때문에 이런 딥 러닝 training dataset을 저장하는데 자주 사용됩니다.

이렇게 LMDB가 생성되고 있는데, 그 data는 어떤 규칙에 의해서 만들어지고 있는 것일까요 ? 그건 오른쪽의 스크롤바를 내려 더 아래쪽으로 내려가보시면 볼 수 있습니다. 보시면 "Input File"이라는 항목에 train.txt라는 text file이 보이지요. 거기에는 각 png file 이름과 그에 따른 label이 정의되어 있고, 그에 따라 LMDB가 생성되고 있습니다.
그 밑에는 그 카테고리, 즉 label에 해당하는 image file들의 숫자가 그래프로 표시되어 있고, 그 그래프 밑에는 'Explore DB'라는 버튼이 보입니다.

이 'Explore DB'라는 버튼을 클릭해보면 아래와 같이 0~9의 숫자마다 어떤 손글씨 그림이 들어있는지를 눈으로 보실 수 있습니다.


LMDB 생성 규칙을 담은 train.txt라는 link를 클릭해보면, 어떤 png file이 어느 숫자로 labeling되어 있는지 보실 수 있습니다. 아래 화면에서는 다 0으로 labeling 되어 있습니다.

좌측 상단의 DIGITS를 click하여 다시 홈페이지로 복귀합니다. 이제 MNIST 라는 dataset을 보실 수 있습니다.

다음으로는 model을 생성하겠습니다. 다음과 같이 Model tab에서 오른쪽 중단의 Images > Classification을 택합니다.

Dataset으로는 방금 생성한 MNIST를 선택합니다.

(여기서부터는 K80이 2장 장착된 Firestone 장비를 구했기 때문에 그것 기준으로 작성했습니다.)
더 밑으로 내려보면 아래와 같이 어떤 신경망을 이용해 training을 할 것인지 정하게 되어 있습니다. 여기서는 LeNet을 선택합니다.

그 밑으로는 몇개의 GPU를 사용하여 training할지 숫자를 적거나, 또는 현재 이 시스템에 장착된 GPU의 종류 및 개수를 보여주며 그 중 어느것을 사용할지 특정하여 선택하게 되어 있습니다. 여기서는 0번과 1번의 2개를 선택하겠습니다. 이렇게 해서 training될 모델의 이름은 LeNet으로 정하겠습니다.

'Create' 버튼을 클릭하면 training이 시작됩니다. (위에서와는 달리 GPU가 장착된 서버이므로) 이젠 training 속도가 매우 빨라서 3분도 채 안 걸릴 것이라는 예상이 나오는 것을 보실 수 있습니다.

스크롤바를 밑으로 내려보면 accuracy와 loss가 실시간 graph로 보여집니다. 가로축은 epoch, 즉 전체 dataset을 몇번 반복해서 training했는지의 횟수인데, accuracy가 첫 epoch에서 이미 98%에 도달한 이후 더 개선이 없는 것을 보실 수 있습니다. 즉, 이런 경우는 여러번 반복 training하는 것이 큰 의미는 없습니다. 아무튼 여기서는 default인 30-epoch 반복하여 training합니다.
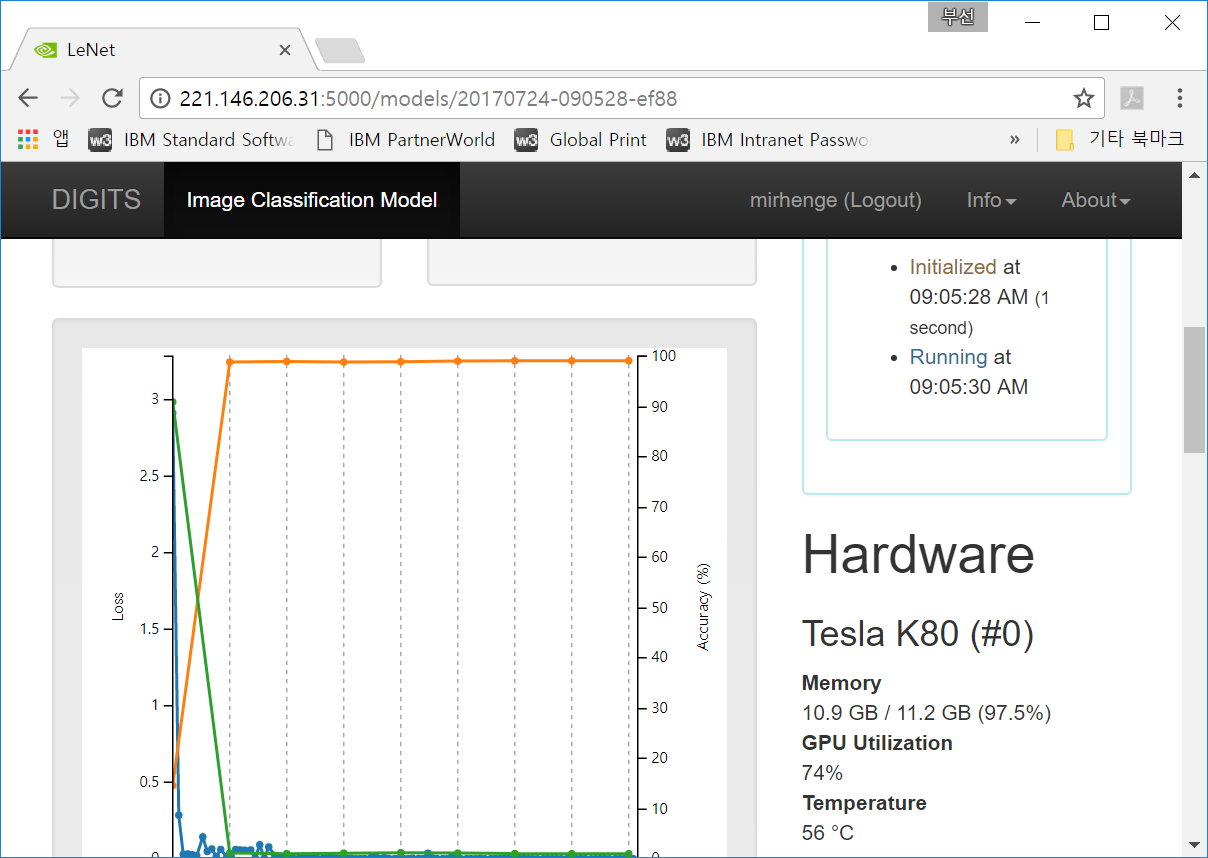
더 아래로 내리면 learning rate가 step size에 따라 계단식으로 줄어드는 것을 보실 수 있습니다. 또한 Caffe process ID 및 그것의 CPU 및 메모리 사용량도 보여줍니다.

아래 시점에서는 이미 19-epoch 반복 training이 끝났고, 그 snapshot이 저장되었기 때문에 'Trained Models'의 'Select Model' 항목에 Epoch #19가 display 되고 있는 것입니다. Training이 원래대로 30회 반복되고 나면 저 숫자가 30까지 display 될 것입니다.

자, 30회 반복되어 training이 끝났습니다. 이제 trained model을 가지고 inference를 해볼 수 있습니다. 아래의 'Test a single image' 항목에서 Image Path에 실제 png file의 full path 이름을 입력합니다.


입력 후 'Classify One' 버튼을 누르면 새 tab이 생기면서 그 결과가 보여집니다.

여기서는 기존 training dataset 중 하나를 넣은 것이므로, 당연히 100% 정확한 답을 맞춥니다.

이번에는 다음과 같이 8과 1이라는 숫자의 이미지의 URL 주소를 가진 text 파일 'URL1.txt'를 upload하여 분류하도록 해보겠습니다.
http://www.clker.com/cliparts/V/1/Y/3/j/Z/blue-number-1-md.png
https://upload.wikimedia.org/wikipedia/commons/c/cf/NShw_8.png
이 URL에서 가리키는 URL은 각각 다음과 같습니다.


저 URL 주소를 가진 'URL1.txt'를 아래와 같이 'Upload Images List' 항목에 입력하고 'Classify Many'를 클릭합니다.


그렇다면 아래처럼 2글자로 된 이미지에는 뭐라고 답을 할까요 ? 참고로 이 LeNet이라는 모델은 하나의 숫자에 대해서만 training이 되어 있습니다.

이번에는 아래처럼 직접 image file을 upload하여 'Classify One' 버튼을 눌러 보겠습니다. 여기서는 특히 'Show visualizations and statistics' 체크 박스도 체크해보겠습니다.

결과는 아래와 같습니다. 3과 8에서 고민하다가 결국 3을 택한 것을 보실 수 있습니다.

그 아래로 내려보면 'Show visualizations and statistics'에 체크를 한 것 때문에 다양한 비주얼라이제이션과 통계치를 보실 수 있습니다.


댓글 없음:
댓글 쓰기