H2O Driverless AI (이하 H2O DAI)의 또다른 유력한 use case인 보험 업무에 대해 살펴보겠습니다. 보험사에게 있어 의료비가 많이 들 것 같은 사람을 골라내는 것은 보험사의 수익과 직결되는 무척 중요한 일입니다. 아래 Kaggle site에서 얻은 환자 기본 정보 및 각 환자에게 든 의료비에 대한 dataset을 이용하여 H2O DAI가 예상 의료비를 얼마나 정확히 측정하는지 테스트 해보겠습니다.
https://www.kaggle.com/mirichoi0218/insurance
이 dataset에는 다음과 같은 칼럼들이 있습니다.
age 나이
sex 성별
bmi 비만도
children 자녀수
smoker 흡연여부
region 사는 지역
charges 의료비
보험사에서 예측하고 싶은 것은 물론 맨 마지막 칼럼인 charges 부분일 것입니다. 이제 H2O DAI를 이용하여 어떻게 이 dataset으로부터 특정 조건을 가진 인물의 예상 의료비를 뽑아낼 수 있는지 step by step으로 알아보시도록 하겠습니다.
1) 웹 브라우저를 통해 H2O DAI에 접속합니다. 맨 처음 menu는 'DATASET'이며, 여러가지 입력 방법 중에서 저는 제 laptop으로부터 upload하는 menu를 택하겠습니다.

2) 저는 위의 Kaggle dataset (insurance.csv)에서 미리 일부 row들을 떼어내어 insurance_test.xlsx를 만들었고, 그 나머지를 insurance_training.xlsx로 저장해놓았습니다. 이것들을 선택하여 H2O DAI에 dataset으로 등록합니다.

3) insurance_training.xlsx와 insurance_test.xlsx가 dataset으로 등록되었습니다. 우측의 'Click for Actions' 부분을 눌러 나오는 sub-menu 중 'DETAILS' 부분을 클릭해 봅니다.

4) 이 DETAILS' 메뉴에서는 이 dataset이 어떤 정보를 담고 있는지 보실 수 있습니다. 각 칼럼별 평균/최대/최소/편차 등의 기본 정보와 최초 20개 row의 값 등을 보실 수 있습니다.

5) Dataset 우측의 'Click for Actions' 부분을 눌러 나오는 sub-menu 중 'VISUALIZATION'을 클릭하면 여러가지 다양한 graph가 자동으로 생성됩니다. 가령 'OUTLIERS PLOT'을 보면 전체 data 중 일부가 표준편차에서 크게 벗어난 것을 보실 수 있습니다. 그런 부분은 표에서 보는 것보다는 이렇게 그래프로 시각화해서 보면 직관적으로 이해하기가 쉽지요. 그렇게 크게 벗어난 오렌지색 점을 클릭해보면 해당 row의 상세 정보를 보실 수도 있습니다.



6) H2O DAI에서 가장 중요한 것은 역시 'PREDICT' 메뉴입니다. 이 메뉴를 통해서 예측 모델을 자동 생성하게 됩니다.

7) 'PREDICT' 메뉴에 들어가면 꼭 하셔야 할 일은 단 하나 밖에 없습니다. 어느 칼럼에 대한 예측 모델을 만드느냐에 대한 선택입니다. 여기서는 당연히 charges 칼럼을 택합니다.


8) 추가로 선택하실 수 있는 메뉴는 중앙 하단의 3개의 라디오 다이얼입니다. 각각의 의미와 강약 조절은 아래와 같습니다. 여기서는 default로 제시된 8-3-8을 그대로 적용하겠습니다.

Accuracy : 어떤 알고리즘들을 몇 개나 적용할지 정합니다. 물론 다이얼 숫자가 높을 수록 더 많은 알고리즘을 적용합니다.
Time : 머신러닝에서 반복 훈련, 즉 iteration을 몇 회나 수행할지 정합니다. 물론 다이얼 숫자가 높을 수록 더 많은 회수가 적용됩니다.
Interpretability : 머신러닝으로 만들어진 모델에 대한 해석의 강도 조절 부분입니다. 다이얼 숫자가 높을 수록 더 단순화해서 해석해줍니다.
9) Launch를 누르면 자동 모델 생성이 시작되고 모델이 training 되는 과정을 보시게 됩니다. 중앙 상단을 보면 그 단계에서 하고 있는 작업과 적용되는 알고리즘 등이 실시간으로 업데이트 되면서 보여집니다. 중앙 하단에는 그 시점까지의 분석 단계에서 판단할 때 가장 중요한 변수/feature, 즉 입력된 dataset의 칼럼 중 어느 칼럼이 가장 중요한 역할을 하더라는 것이 실시간으로 분석되어 보여집니다. 가령 3% 경과된 시점에서는 LIGHTGBM 알고리즘을 처리 중이고, 흡연여부-비만지수-나이 순으로 병원비에 중요한 영향을 끼친다고 나옵니다.



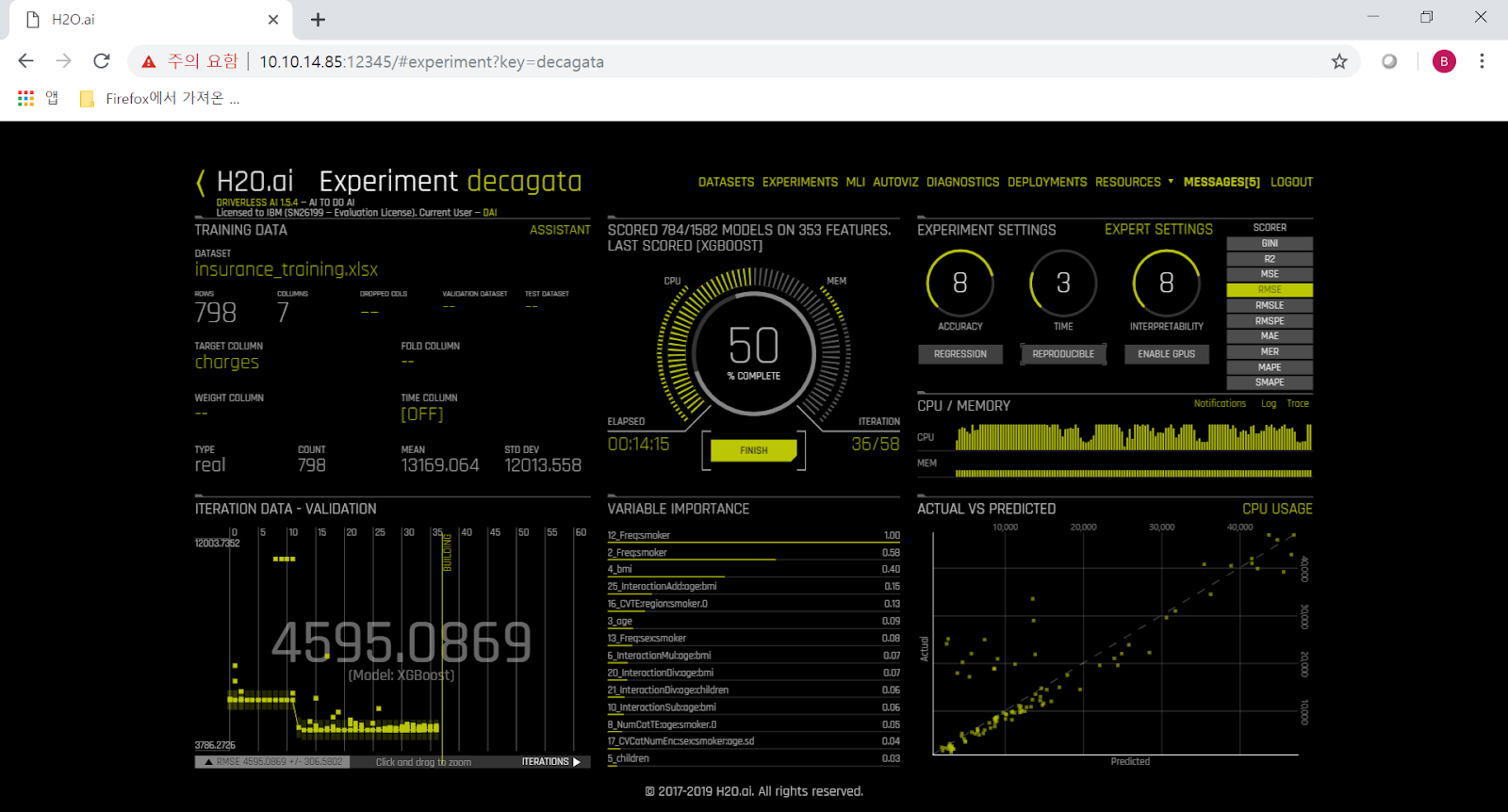
10) 그러나 auto feature engineering이 본격적으로 시작되면서 경과%가 진행되면서 그 값들은 계속 변화합니다. 가령 79% 경과 진행 중일 때는 무려 497개의 feature에 대해 1582개의 model에 대해서 평가 중이라고 나오지요. 원래 dataset의 칼럼 수, 즉 feature 수가 7개 밖에 없었다는 점을 생각하면 H2O DAI가 정말 다양한 조합의 feature engineering을 자동으로 수행하고 있다는 점을 아실 수 있습니다. 그 결과로 나오는 중앙 하단의 'Variable Importance', 즉 어떤 변수/feature가 병원비 지출액에 가장 중요한 영향을 끼치더라는 점도 비만도와 성별, 그리고 흡연여부가 결합되어 새로 생성된 변수를 가장 중요시하는 것을 보실 수 있습니다. 그 항목들을 자세히 보시면, 정말 모든 경우에 흡연여부가 가장 중요한 영향을 끼친다는 것을 보실 수 있습니다. 흡연인 여러분, 아무래도 담배는 끊으셔야 할 것 같습니다.

11) 모델 생성이 완료되면 우측 하단에 요약 설명이 나옵니다. 그러나 가장 중요한 것은 중앙 상단 메뉴의 3번쨰 항목, 즉 'SCORE ON ANOTHER DATASET' 입니다. 여기에 우리가 원하는 charges 값을 뺀 다른 값들 (연령, 사는 곳, 성별, 흡연 여부 등)이 들어있는 표를 입력하면, 해당 사람들이 얼마나 병원비를 쓸지 예측한 값을 출력해주거든요. 여기서는 미리 입력해둔 insurance_test.xlsx를 test dataset으로 선택하겠습니다. 그러면 곧장 해당 사람들의 병원비(charges) 값을 예측하여 그 결과를 csv 파일로 download 시켜줍니다.



12) 그렇게 해서 얻은 해당 환자들의 예상 병원비와 실제 병원비의 결과는 아래 그래프와 같습니다. 파란 곡선이 실제값이고, 오렌지색 곡선이 H2O DAI가 예측한 값입니다. 놀랍도록 잘 맞춘 것을 보실 수 있습니다. 다만 중간 정도에 H2O DAI는 7천4백불 정도를 예상했는데 실제로는 2만8천불을 사용하여 H2O DAI의 예상이 크게 틀린 환자가 있습니다. 이 환자의 상태를 보면, BMI 지수가 높은 비흡연자입니다. 아마도 H2O DAI가 만든 모델에서는 BMI 지수는 그다지 중요하지 않고 흡연 여부가 가장 중요했는데, 이 환자의 경우는 그 예측이 빗나간 것 같습니다.

13) 위에서 BMI 지수니 흡연여부니 하는 것은 어디까지나 저 개인의 짐작에 불과할 뿐 수학적인 모델로 계산한 결과는 아닙니다. 왜 이 머신러닝 모델이 이런 예측값을 내놓았는지 해석하는 것이 바로 MLI (Machine Learning Interpretation)입니다. H2O는 K-LIME과 Decision Tree, Random Forest 등 다양한 MLI 기능을 제공합니다. 그런 MLI는 모델 생성 완료시의 메뉴 맨 상단의 'Interpret This Model'을 클릭함으로써 생성할 수 있습니다.

14) 이런 MLI 해석 결과도 어느 정도 data science에 대한 소양이 있어야 볼 수 있는 것이 사실입니다. 가령 LIME이 무엇인지 알아야 이해를 할 수 있으니까요. (참고로 LIME은 Locally Interpretable Model-agnostic Explainations을 뜻하는 말로서, 어떤 모델을 생성할 때 사용된 변수 값을 하나씩 바꿔보고 그 모델의 결과에 얼마나 변화가 생기는지 봄으로써 어느 변수가 가장 중요한 역할을 하는지 해석하는 기법입니다.) 하지만 H2O DAI는 일반인들도 이해하기 쉬운 설명도 제시합니다.



15) 가령 Summary 부분의 맨 아래는 원래 dataset의 칼럼 중에서 어느 칼럼이 가장 중요한 역할을 하는지 보여줍니다.

16) KLIME에서는 각각의 예측값에 대해, 어떤 변수가 어느 정도의 영향을 끼쳤는지를 수식화해서 보여줍니다.

17) 가장 쉬운 설명은 KLIME 메뉴 중 중앙상단의 'Explanations' 버튼을 클릭하면 볼 수 있습니다. 여기서는 흡연여부, BMI 지수 등의 변수의 증감에 따라 우리가 알고자 하는 target (여기서는 병원비)의 증감이 어떻게 변화하는지 최대한 단순화하여 제시합니다. 여기에 제시된 설명에 따르면 흡연여부가 가장 중요하고, 자녀가 있는지 여부가 그 다음이며, 사는 곳이 어디인지도 꽤 큰 영향을 미치는 것 같습니다. 아마 부유한 동네인지 또는 그 지방의 식습관 등이 영향을 주는 것일까요 ? 왜 그런지 모르겠습니다만 이 예측 모델에서는 의외로 BMI 지수, 즉 비만 여부는 상대적으로 그다지 큰 영향을 주지는 않는다고 판단하고 있습니다.

이 포스팅의 결론은 다음과 같습니다.
1. H2O DAI는 무척 정확한 예측 모델을 정말 쉽게 만들어낼 수 있을 뿐만 아니라, 왜 그런 예측을 했는지도 매우 쉽게 풀어서 설명해줍니다.
2. 흡연자 여러분, 금연 합시다.
https://www.youtube.com/watch?v=niiibeHJtRo&t=1321s 보면 무슨 데이터사이언티스를(어느정도)대체 해줄 것 처럼 말해주는데 ......
답글삭제사용방법이나 해석하는게 만만치 않네요 ..