Kaggle이라는 것은 일종의 data science 경쟁 대회라고 보시면 됩니다. 국가기관이나 기업 등에서 자신들이 해석하기 어려운 (주로 비인식처리된) 실제 data를 올려놓고 전세계 scientist들에게 그 분석 방법에 대해 경쟁을 벌이도록 하는 것입니다. 저는 data scientist와는 100만 광년 정도의 거리에 있는 일개 시스템 엔지니어입니다만, H2O Driverless AI의 힘을 빌어 아래의 신용카드 사기 예측 모델 생성에 도전해보겠습니다.
https://www.kaggle.com/mlg-ulb/creditcardfraud/home
여기서 제공되는 data는 https://www.kaggle.com/mlg-ulb/creditcardfraud/downloads/creditcardfraud.zip 에 올려져 있습니다. Facebook이나 Google 등으로 로그인해야 download가 가능합니다.
압축을 풀면 다음과 같이 28만이 넘는 row를 가진 csv 파일을 얻을 수 있습니다. 이 중 마지막 3천 row를 뚝 잘라 creditcard_test1.csv로 만들고, 나머지 것을 creditcard_train.csv으로 쓰겠습니다.
[bsyu@redhat74 data]$ wc -l creditcard.csv
284808 creditcard.csv
[bsyu@redhat74 data]$ ls -l creditcard*.csv
-rw-rw-r-- 1 bsyu bsyu 150828752 Mar 23 2018 creditcard.csv
[bsyu@redhat74 data]$ head -n 1 creditcard.csv > creditcard_test.csv
[bsyu@redhat74 data]$ tail -n 3000 creditcard.csv >> creditcard_test1.csv
[bsyu@redhat74 data]$ head -n 283808 creditcard.csv > creditcard_train.csv
각 row는 아래와 같이 비식별화처리를 거친 모종의 값으로 되어 있습니다. 여기서 비식별화처리가 되지 않은 column은 맨마지막 2개, 즉 Amount와 Class입니다. Amount는 카드 사용금액이고, Class가 0이면 정상거래, 1이면 사기거래입니다.
[bsyu@redhat74 data]$ head -n 2 creditcard_train.csv
"Time","V1","V2","V3","V4","V5","V6","V7","V8","V9","V10","V11","V12","V13","V14","V15","V16","V17","V18","V19","V20","V21","V22","V23","V24","V25","V26","V27","V28","Amount","Class"
0,-1.3598071336738,-0.0727811733098497,2.53634673796914,1.37815522427443,-0.338320769942518,0.462387777762292,0.239598554061257,0.0986979012610507,0.363786969611213,0.0907941719789316,-0.551599533260813,-0.617800855762348,-0.991389847235408,-0.311169353699879,1.46817697209427,-0.470400525259478,0.207971241929242,0.0257905801985591,0.403992960255733,0.251412098239705,-0.018306777944153,0.277837575558899,-0.110473910188767,0.0669280749146731,0.128539358273528,-0.189114843888824,0.133558376740387,-0.0210530534538215,149.62,"0"
이 dataset은 Class 측면에서 보면 굉장히 빈도가 낮은 것입니다. 즉, 전체 28만건이 넘는 거래들 중, 사기거래, 즉 Class가 1인 거래는 고작 492건에 불과합니다. Percentage로 따지면 고작 0.173%에 불과합니다. 보통 machine learning에서 만든 모델의 정확도가 90%를 넘어가면 꽤 성공적이라고들 하는데, 이런 경우에는 어떤 거래를 판정하라는 요청을 받았을 때 그냥 무조건 정상거래라고 판정하면 99.8% 이상의 정확도를 나타냈다고(?) 주장할 수도 있습니다. 과연 이런 극악한 조건에서 H2O Driverless AI는 제대로 된 모델을 만들 수 있을까요 ?
[bsyu@redhat74 data]$ cut -d"," -f31 creditcard.csv | grep 1 | wc -l
492
우리의 목표는 이 data를 이용해서 어떤 거래가 사기인지 정상인지 판별하는 model을 만드는 것입니다. 그 성공 여부 판별을 위해 잘라낸 test dataset 3천 row 중에 실제 사기 건수는 얼마나 될까요 ? 고작 4건입니다. 588번째, 871번째, 874번째, 그리고 921번째 row입니다.
[bsyu@redhat74 data]$ cut -d"," -f31 creditcard_test1.csv | grep 1
"1"
"1"
"1"
"1"
[bsyu@redhat74 data]$ cut -d"," -f31 creditcard_test1.csv | head -n 589 | tail -n 5
"0"
"0"
"0"
"1"
"0"
[bsyu@redhat74 data]$ cut -d"," -f31 creditcard_test1.csv | head -n 875 | tail -n 7
"0"
"0"
"1"
"0"
"0"
"1"
"0"
[bsyu@redhat74 data]$ cut -d"," -f31 creditcard_test1.csv | head -n 923 | tail -n 5
"0"
"0"
"1"
"0"
"0"
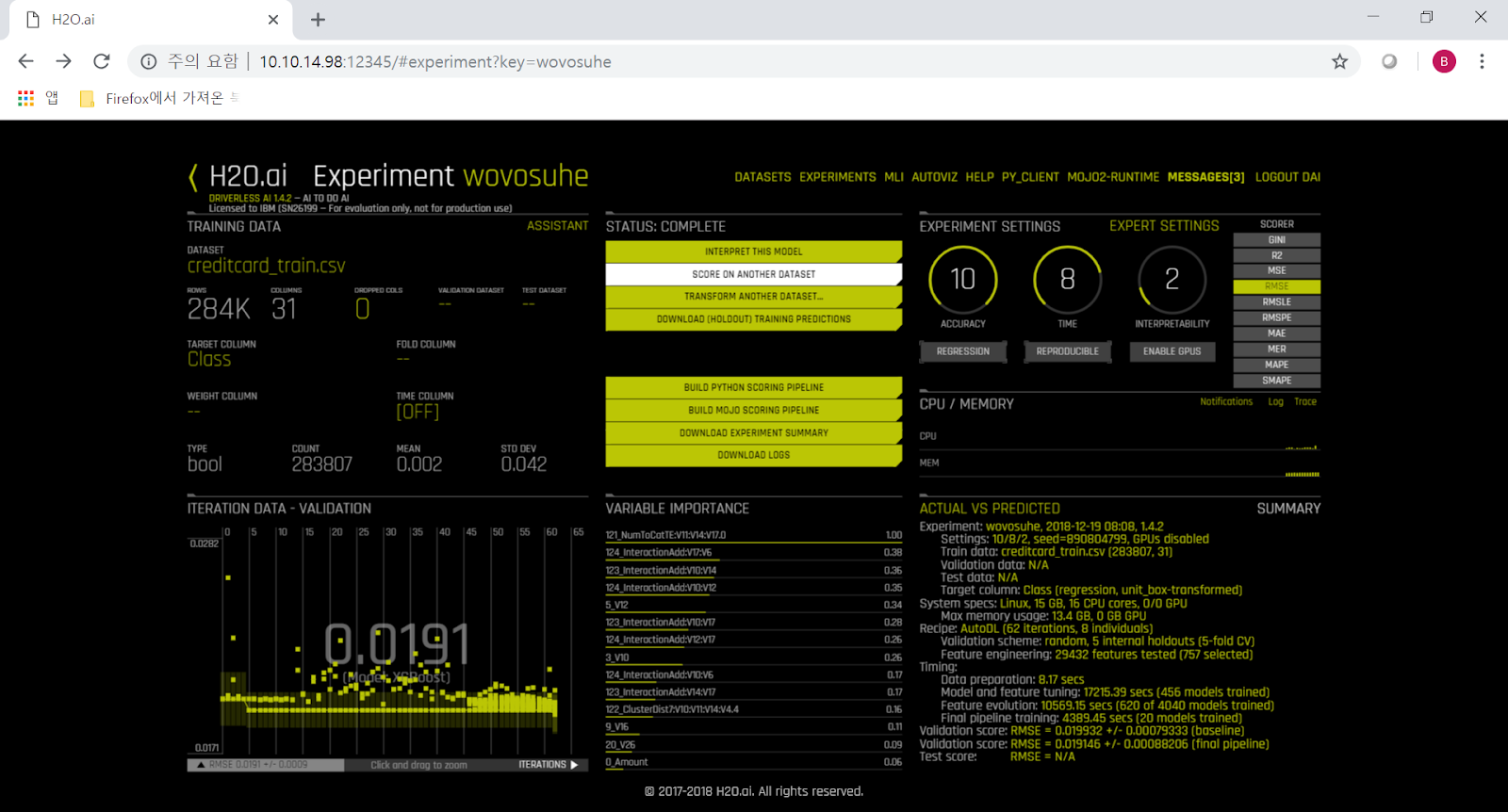
다음과 같이 H2O Driverless AI에 creditcard_train.csv를 add 하고 target column은 'Class'로 지정한 뒤, control knob은 Accuracy 10, Time 8, Interpretability 2로 맞추고 training (H2O 용어로는 experiment)를 시작했습니다. Accuracy 항목에서 Regression으로 수행하고 있기 때문에, 결과 예측값은 0이나 1의 숫자가 아닌, 그 중간의 소수로 나올 것입니다. 그 값이 1에 가까울 수록 사기일 확률이 높고, 0에 가까울 수록 정상거래일 것입니다.

참고로 이번에는 GPU를 갖춘 시스템을 구하지 못해서, POWER8 가상 머신에서 CPU core 2개를 이용해서 수행했습니다. SMT=8으로 되어 있기 때문에, OS에게는 이것이 2개의 core가 아닌 16개의 logical CPU로 인식됩니다. 덕분에 CPU 사용률이 매우 높고, 또 시간도 엄청나게 오래 걸리는 것을 보실 수 있습니다.

최종적으로 만들어진 model은 크기가 무려 7GB나 되고, 만드는데 거의 9시간이 걸렸습니다.

이제 이 model을 열어 test dataset으로 판별을 해보겠습니다. 맨 처음에 training을 시작할 때 RMSE (root mean square error)가 0.0194로 시작했었는데, 최종적으로는 0.0191로 약간 줄어있는 것을 보실 수 있습니다.
Score on Anonther Dataset을 클릭하면 dataset을 선택하게 되어 있는데, 미리 서버에 올려둔 creditcard_test1.csv을 선택하면 약 1분 정도 prediction이 수행된 뒤에 그 결과로 (input인 creditcard_test1.csv가 3천 row이므로) Class column에 대한 3천 row의 예측값을 담은 csv 파일을 download 할 수 있게 해줍니다. 그 결과는 아래와 같습니다.



최소한 정상거래를 사기거래라고 판정한 것은 하나도 없습니다. 대부분의 row는 사기 확률이 0%로 나오고, 실제로는 사기였던 4개 row에 대해서는 위와 같이 나옵니다. 즉 2개는 98%, 99%로서 사기가 확실하고, 나머지 2개는 사기 확률이 36%와 49%로 나오는 것이지요. 이 정도면 상당히 높은 수준의 결과라고 판단됩니다. 정말 멋지지 않습니까 ?
---------------------------
추가로, training dataset을 좀더 작게, 대신 test dataset을 좀더 크게 하여 model을 생성하고 테스트해보겠습니다. 아래와 같이, 전체 28만4천건 중에 26만건을 training dataset으로, 그리고 나머지 2만4천건을 test dataset으로 잘라냈습니다.
[bsyu@redhat74 data]$ wc -l credi*
284808 creditcard.csv
[bsyu@redhat74 data]$ head -n 260001 creditcard.csv > credit_train.csv
[bsyu@redhat74 data]$ head -n 1 creditcard.csv > credit_test.csv
[bsyu@redhat74 data]$ tail -n 24807 creditcard.csv >> credit_test.csv
[bsyu@redhat74 data]$ wc -l creditcard.csv credit_train.csv credit_test.csv
284808 creditcard.csv
260001 credit_train.csv
24808 credit_test.csv
이것을 다음과 같이 Accuracy 10, Time 7, Interpretability 2로 맞추고 training 했습니다.

그 결과로 (역시 GPU 없이 POWER8 CPU core 2개만 이용해서) training 하는데 총 13시간 정도가 걸렸습니다.

이 자동생성된 model을 이용하여 위에서 준비한 2만4천건의 test dataset인 credit_test.csv에 대한 prediction을 수행했고, 그 결과로 gerewika_preds_799411be.csv 파일을 얻었습니다.
[bsyu@redhat74 data]$ head /tmp/gerewika_preds_799411be.csv
Class
4.00790426897506e-5
2.7836374905953808e-5
4.3067764191826185e-5
6.776587835599978e-5
0.0007914757505702477
0.00026333562696054583
0.0003490925939070681
0.00012611508177717525
3.6875439932445686e-5
위에서 준비했던 credit_test.csv 속에는 과연 사기 건수가 몇건이었을까요 ? 그 column 중 31번째 column인 Class의 값이 1인 것이 몇건인지를 세어보겠습니다.
[bsyu@redhat74 data]$ cut -f31 -d',' ./credit_test.csv | grep 1 | wc -l
21
과연 우리가 얻은 gerewika_preds_799411be.csv 파일 속에서 사기일 가능성이 높은 칼럼은 몇 개일까요 ? 그것을 세기 위해 다음과 같은 script를 만들었습니다.
[bsyu@redhat74 data]$ cat count.sh
if [[ $# -ne 2 ]]
then
echo "Usage ./count.sh digit filename"
fi
j=1
for i in `cat $2 `
do
m=$(printf "%f" "$i")
if (( $(echo "$m >= $1" | bc -l) ))
then
echo "Row_num is $j and the vlaue is $m"
fi
(( j=j+1 ))
done
여기서 몇 %일 때 이를 사기로 볼 것인지는 여러분이 직접 정하셔야 합니다. 일단 70%, 즉 0.70 이상이면 사기로 간주하는 것으로 해서 세어보겠습니다.
[bsyu@redhat74 data]$ ./count.sh 0.7 /tmp/gerewika_preds_799411be.csv
./count.sh: line 9: printf: Class: invalid number
Row_num is 1058 and the vlaue is 0.740187
Row_num is 1475 and the vlaue is 0.897596
Row_num is 1927 and the vlaue is 0.975030
Row_num is 2562 and the vlaue is 0.996552
Row_num is 2828 and the vlaue is 0.968835
Row_num is 3276 and the vlaue is 0.979910
Row_num is 3326 and the vlaue is 0.939915
Row_num is 3879 and the vlaue is 0.896258
Row_num is 16866 and the vlaue is 0.995111
Row_num is 19865 and the vlaue is 0.958619
Row_num is 20145 and the vlaue is 0.905748
Row_num is 20151 and the vlaue is 0.911095
Row_num is 21146 and the vlaue is 0.964987
Row_num is 1058 and the vlaue is 0.740187
Row_num is 1475 and the vlaue is 0.897596
Row_num is 1927 and the vlaue is 0.975030
Row_num is 2562 and the vlaue is 0.996552
Row_num is 2828 and the vlaue is 0.968835
Row_num is 3276 and the vlaue is 0.979910
Row_num is 3326 and the vlaue is 0.939915
Row_num is 3879 and the vlaue is 0.896258
Row_num is 16866 and the vlaue is 0.995111
Row_num is 19865 and the vlaue is 0.958619
Row_num is 20145 and the vlaue is 0.905748
Row_num is 20151 and the vlaue is 0.911095
Row_num is 21146 and the vlaue is 0.964987
Row_num is 1058 and the vlaue is 1.000000
Row_num is 1475 and the vlaue is 1.000000
Row_num is 1927 and the vlaue is 1.000000
Row_num is 2562 and the vlaue is 1.000000
Row_num is 2828 and the vlaue is 1.000000
Row_num is 3082 and the vlaue is 1.000000
Row_num is 3276 and the vlaue is 1.000000
Row_num is 3326 and the vlaue is 1.000000
Row_num is 3879 and the vlaue is 1.000000
Row_num is 8377 and the vlaue is 1.000000
Row_num is 12523 and the vlaue is 1.000000
Row_num is 14384 and the vlaue is 1.000000
Row_num is 14477 and the vlaue is 1.000000
Row_num is 15994 and the vlaue is 1.000000
Row_num is 16073 and the vlaue is 1.000000
Row_num is 16866 and the vlaue is 1.000000
Row_num is 19865 and the vlaue is 1.000000
Row_num is 20145 and the vlaue is 1.000000
Row_num is 20151 and the vlaue is 1.000000
Row_num is 21146 and the vlaue is 1.000000
Row_num is 21676 and the vlaue is 1.000000
-----------------------------------------------
이하는 상기 model을 training한 뒤 얻은 MLI (machine learning interpretation) 항목의 결과입니다.
가장 알아보기 쉬운 KLIME의 설명을 보면 다음과 같습니다. 아래 그림에도 있습니다만, Class 항목이 1 증가할 때 V11은 0.0058 증가, V4는 0.0036 증가... 등의 상관관계를 Driverless AI가 분석해냈습니다.
Top Positive Global Attributions
V11 increase of 0.0058
V4 increase of 0.0036
V2 increase of 0.0024







이하는 상기 model을 training한 뒤 얻은 MLI (machine learning interpretation) 항목의 결과입니다.
가장 알아보기 쉬운 KLIME의 설명을 보면 다음과 같습니다. 아래 그림에도 있습니다만, Class 항목이 1 증가할 때 V11은 0.0058 증가, V4는 0.0036 증가... 등의 상관관계를 Driverless AI가 분석해냈습니다.
Top Positive Global Attributions
V11 increase of 0.0058
V4 increase of 0.0036
V2 increase of 0.0024







추가 테스트를 해봤습니다. 다음과 같이 약 250000번째 줄부터 4000 줄을 빼내어 credit_test.csv라는 test용 dataset을 만들고, 그 4000 줄을 뺀 나머지 부분으로 credit_train.csv이라는 training용 dataset을 만들었습니다.
ibmtest@digits:~/files/csv$ head -n 250001 creditcard.csv > credit_train.csv
ibmtest@digits:~/files/csv$ tail -n 30808 creditcard.csv >> credit_train.csv
ibmtest@digits:~/files/csv$ head -n 1 creditcard.csv > credit_test.csv
ibmtest@digits:~/files/csv$ head -n 254809 creditcard.csv | tail -n 4000 >> credit_test.csv
ibmtest@digits:~/files/csv$ wc -l credit_train.csv credit_test.csv
280809 credit_train.csv
4001 credit_test.csv
284810 total
Training용 dataset에는 class가 1, 즉 사기 transaction이 총 484개 들어있고, test용 dataset에는 9개 들어있습니다.
ibmtest@digits:~/files/csv$ cut -f31 -d',' ./credit_train.csv | grep 1 | wc -l
484
ibmtest@digits:~/files/csv$ cut -f31 -d',' ./credit_test.csv | grep 1 | wc -l
9
이제 test용 dataset 중 몇번째 row가 사기 transaction인지 row #를 찾아보겠습니다.
ibmtest@digits:~/files/csv$ j=1
ibmtest@digits:~/files/csv$ for i in `cut -f31 -d',' ./credit_test.csv`
> do
> if [ "$i" == "\"1\"" ]
> then
> echo "Row_num is " $j
> fi
> ((j=j+1))
> done
Row_num is 671
Row_num is 1060
Row_num is 1075
Row_num is 1085
Row_num is 1098
Row_num is 1318
Row_num is 1968
Row_num is 3538
Row_num is 3589
이제 H2O DAI로 training을 한 뒤, 이 test dataset을 넣어서 예측을 해보았습니다. 그 결과는 다음과 같습니다.
30% (0.3)을 기준으로 하면 아래와 같이 9건 중 6건을 찾아냅니다.
ibmtest@digits:~/files/csv$ ./count.sh 0.3 miwatuvi_preds_c5262e68.csv
./count.sh: line 8: printf: Class: invalid number
Row_num is 671 and the vlaue is 1.000000
Row_num is 1060 and the vlaue is 0.950008
Row_num is 1098 and the vlaue is 0.904203
Row_num is 1318 and the vlaue is 1.000000
Row_num is 1968 and the vlaue is 1.000000
Row_num is 3538 and the vlaue is 0.303216
20% (0.2)을 기준으로 하면 아래와 같이 9건 중 7건을 찾아냅니다.
ibmtest@digits:~/files/csv$ ./count.sh 0.2 miwatuvi_preds_c5262e68.csv
./count.sh: line 8: printf: Class: invalid number
Row_num is 671 and the vlaue is 1.000000
Row_num is 1060 and the vlaue is 0.950008
Row_num is 1098 and the vlaue is 0.904203
Row_num is 1318 and the vlaue is 1.000000
Row_num is 1968 and the vlaue is 1.000000
Row_num is 3538 and the vlaue is 0.303216
Row_num is 3589 and the vlaue is 0.296002
댓글 없음:
댓글 쓰기