IBM의 이미지 및 동영상을 위한 classification/object detection용 솔루션인 PowerAI Vision의 사용법을 정리했습니다.
먼저, image dataset에 대해 labeling을 해야 합니다. 이는 인터넷 상에서 쉽게 구할 수 있는 무료 tool인 labelimg, imageio 등을 이용하셔도 되고, 아예 처음부터 PowerAI Vision (이하 PAIV) 속에서 수행하셔도 됩니다. 아래의 예는 labelimg를 이용하여 사진 속의 object에 사각형을 그리고 labeling을 하는 장면입니다.

이런 식으로 labeling을 하면 그 결과가 해당 파일 하나마다 한개씩 xml 파일이 생성되어 저장됩니다. 이렇게 사진마다 labeling xml 파일이 생성되면 파일들을 PAIV에 upload할 준비가 된 것입니다. 이 사진 및 xml 파일들을 PAIV에 upload할 때 더 간편하게 할 수 있도록 아예 zip 파일로 묶어놓으면 더 좋습니다.

참고로 이 labeling xml 파일의 내용은 아래와 같습니다.

이제 web browser를 통해 PAIV에 접속하겠습니다. 기본 userid/passwd는 admin/passw0rd입니다. 접속하고나면 맨 먼저 'Data sets' 항목으로 갑니다. 기존에 다른 분들이 upload하신 dataset들이 있고 수지씨의 아름다운 사진도 보입니다만 한눈 팔지 마시고 우리는 'Create New Data Set'을 클릭합니다.

'Data Set Name'에 적절한 이름을 붙이십시요.

그러고나면 우리가 만든 fighter라는 dataset이 생성된 것을 보실 수 있습니다. 그러나 여기에는 아직 사진이 한장도 들어있지 않습니다. 이제 여기에 사진을 넣어야 합니다.

우리가 만든 fighter라는 dataset을 클릭하면 '파일을 여기에 끌어놓으라'는 메시지와 'Import files'라는 사각버튼이 보입니다. 여기서는 이 사각버튼을 눌러 보겠습니다.

이건 평범하게, 우리가 쓰고 있는 PC의 directory로부터 파일을 upload할 수 있는 메뉴를 불러옵니다. 여기서는 아까 zip으로 압축해놓았던 fighter.zip을 선택합니다.


이제 보면 fighter.zip 속에 들어있는 사진들과 xml 파일을 PAIV가 읽어들여 dataset으로 포맷한 것으로 보실 수 있습니다. 다만 사진들을 보면 작은 글씨로 f16, f15 등이 아까 우리가 labeling해놓은 대로 표시되어 있으나, 사진 위에는 큰 글씨로 'Uncategorized' 라고 분류된 것을 보실 수 있습니다. 이는 위에서 우리가 했던 label은 사진 속의 object에 붙여놓은 것이고, 사진 전체에 대해 f15, f16 등으로 분류하는 label을 붙여놓은 것은 아니기 때문입니다. 즉, 이 사진들은 classification을 위해서 label이 된 것이 아니라 object detection을 위해서 label이 된 것입니다.
여기서 잠깐 classification과 object detection을 구분하자면 아래와 같습니다.
Classification : 사진 1장 전체를 미리 지정한 category 중 어느 하나로 분류
Object detection : 사진 내에 미리 지정된 object에 해당하는 것이 있는지 감지하여 사각형으로 표시
우리의 dataset에는 크기 f15, f16, f14의 3가지 object들이 들어있습니다. 이것들을 모두 택하시고, 이제 'Train'이라는 사각버튼을 눌러 training에 들어가겠습니다.

Train 메뉴에서는 먼저 'Type of training'을 'Image classification'과 'Object detection' 둘 중 하나에서 선택해야 합니다. 물론 이 dataset labeling 특성에 맞게 우리는 'Object detection'을 택해야 합니다. ('Image classification'을 택하려면 먼저 사진의 labeling을 그에 맞게 해야 하는데, 그건 뒤에서 다시 보시겠습니다.) 이어서 그 아래의 'Model selection'을 해야 하는데, 여기서는 'Optimized for accuracy (faster R-CNN)'을 택했습니다.

그 아래의 'Advanced options' 메뉴는 max interation이나 learning rate 같은 hyperparameter를 지정하는 곳입니다. 여기서는 아무 수정 없이 그냥 train 하겠습니다. 아래의 'Train' 사각버튼을 누르면 train이 시작됩니다.

Train이 시작되면 이 과정이 얼마나 더 걸리는지가 대략 계산되어 display 됩니다.

그 아래 화면에서는 iteration이 진행됨에 따라 감소하는 loss graph가 display 됩니다.

Training이 완료되면 'Model details'와 'Deploy'의 2가지 사각버튼이 보입니다. 이 중 먼저 'Model details'를 클릭하겠습니다.

여기서는 train된 model에 대한 간단한 정보들이 display됩니다. Accuracy와 Precision, mAP 등이 무엇을 뜻하는지는 아래 URL을 참조하시기 바랍니다.
https://www.ibm.com/support/knowledgecenter/SSRU69_1.1.2/base/vision_metrics.html#vision_metrics__detection_gpu


이제 맨 위의 'Deploy model' 사각버튼을 눌러보겠습니다. 아래와 같이 model의 이름을 정하고 엔터를 누르면 'Deployed models'에 방금 생성한 model의 이름이 나타나게 됩니다.


우리가 방금 생성한 model 이름을 클릭해 봅니다. 그러면 이 모델이 Image classification을 위한 것인지 Object detection을 위한 것인지가 표시되면서, 외부에서 이 model을 불러쓸 수 있도록 API endpoint도 display됩니다. 여기서는 그 밑에 있는 'Tes Model' 메뉴에 별도의 사진을 넣어 제대로 object를 탐지하는지 시험해보겠습니다. 시험 방법은 간단합니다. 그냥 PC의 파일관리자에서 원하는 사진을 끌어다 'Drop files here'라고 쓰인 흰색 상자에 넣기만 하면 됩니다.


보셨다시피 training dataset에 사진이 몇장 없었기 때문에, 이 모델의 실제 정확도는 매우 낮습니다. 그래서 F14 전투기를 F16으로 분류하기도 합니다만, 겉으로 꽤 비슷해 보이는 F14와 F15를 훌륭하게 제대로 구분해서 보여주기도 합니다.



이번에는 처음에 만들었던 'fighter' dataset으로 되돌아가보겠습니다. 메뉴 화면 중에 'Augment data'라는 것이 보일 것입니다. 그걸 클릭해보면, blur/color/sharpen/rotate/crop/noise 등과 같은 기법을 통해 1장의 사진을 여러장으로 가공하여 사진 수를 늘리는 메뉴임을 아실 수 있습니다. 여기서는 blur와 color 빼고 모든 기법을 다 택하고 'Continue'를 눌러보겠습니다.


아래와 같이 새로 추가될 증강 dataset에 'fighter_augmented'라고 이름을 붙여주고나면, 그 이름으로 새로운 dataset이 추가된 것을 보실 수 있습니다. 그리고 그 속의 사진 개수는 원래 24장이던 것이 무려 528장으로 늘어나 있습니다. 이제 그 'fighter_augmented' dataset을 클릭해보겠습니다.


실제로 하나의 사진이 blur라든가 rotate 등의 기법으로 여러 장으로 복제된 것을 보실 수 있습니다. 이 528장의 사진을 가지고 이번에는 object detection이 아닌 classification을 수행해보도록 하겠습니다.

위의 사진들 중 f16에 해당하는 사진들을 click한 뒤, 사진 위의 메뉴 중 'Assign category'를 클릭하십시요. 그리고 거기에 category 이름을 f14, f15, f16 등으로 지정하면 됩니다.


이제 아래 dataset과 같이 각 사진마다 f14, f15, f16 중 하나의 category가 지정되었습니다. 이제 'Train model' 사각버튼을 눌러 train을 시작합니다.

'Type of training' 항목에서는 아까와는 달리 'Object detection' 대신 'Image Classification'을 선택합니다. 그 아래의 'Model selection'에서는 시스템에서 제공하는 기본 neural network인 'GoogleNet'을 선택합니다. 아직은 Caffe에서의 GoogleNet만 기본 지원되지만, 그 밑의 'Custom Model'을 선택하면 외부에서 가져온 tensorflow의 다른 neural network도 import 하여 사용할 수 있습니다.

그 밑의 'Advanced options'에서는 'Base model'을 선택하게 되어 있습니다. 대부분의 경우엔 'General'을 택하겠습니다만, 혹시 우리가 지금 train하려는 dataset이 PAIV에서 기본으로 제공되는 trained model인 '풍경, 얼굴, 자동차' 등에 해당하는 것이라면, 이 기본 model에 대해 추가 dataset으로 추가 train 하는 형태로 진행할 수 있습니다. 그 경우 더 높은 정확도를 얻을 수 있겠지요. 불행히도 우리는 여기서 전투기 사진을 사용하고 있으므로 해당 사항이 없고, 따라서 'General'을 택해야 합니다.

나머지 부분은 learning rate 등의 hyper parameter setting입니다. 여기서는 변경하지 않고 'Train' 사각버튼을 눌러 train을 시작합니다.

그 다음 부분은 위에서 한번 해본 object detection과 동일합니다. Model training이 끝나면 해당 model을 적당한 이름으로 save하고, 이어서 deploy하면 그 이름이 Deployed models 목록에 나타나는 것을 보실 수 있습니다.




방금 deploy한 'fighter_augmented_model_deployed'를 클릭하여 들어가보면, 아까의 object detection 모델과 같이 'API endpoint' 정보 등과 함께, 'Test Model' 메뉴가 나옵니다. 여기에 별도로 준비한 전투기 사진을 drag & drop으로 넣어서 제대로 classification을 하는지 보겠습니다.

이 classification model은 아까의 object detection model에 비해 (비록 실제로 다양한 사진을 넣은 것이 아니라 augmented dataset에 불과하지만) 훨씬 많은 dataset을 사용해서 train했기 때문인지, 아까의 object detection보다는 훨씬 더 나은 정확도를 보여줍니다. 비록 도중에 F14를 F16이라고 분류한 것이 있긴 합니다만, 전투기에 별 관심 없는 사람이라면 구별하기 힘든 F14와 F15를 매우 잘 분류하고 있습니다.






이번에는 PAIV가 자랑하는 특수 기능인 'Auto labeling'을 시도해보겠습니다. 이는 기존에 train해둔 model을 이용하여, 새로 추가된 dataset에 대해 object label을 자동으로 수행해주는 기능입니다. 많은 일손과 시간이 들어가는 label 수작업을 크게 줄여주는 고마운 기능입니다. 다만 이 기능에 대해서는 2가지를 염두에 두셔야 합니다.
1) Classification은 지원하지 않으며, Object detection을 위한 labeling만 지원합니다.
2) Auto labeling에 사용한 기존 model의 accuracy가 좋지 않으면, 당연히 auto labeling의 품질도 떨어집니다.
Auto labeling을 수행하기 위해, 먼저 추가의 전투기 사진들로 새로운 dataset 'more_fighters'를 만듭니다.


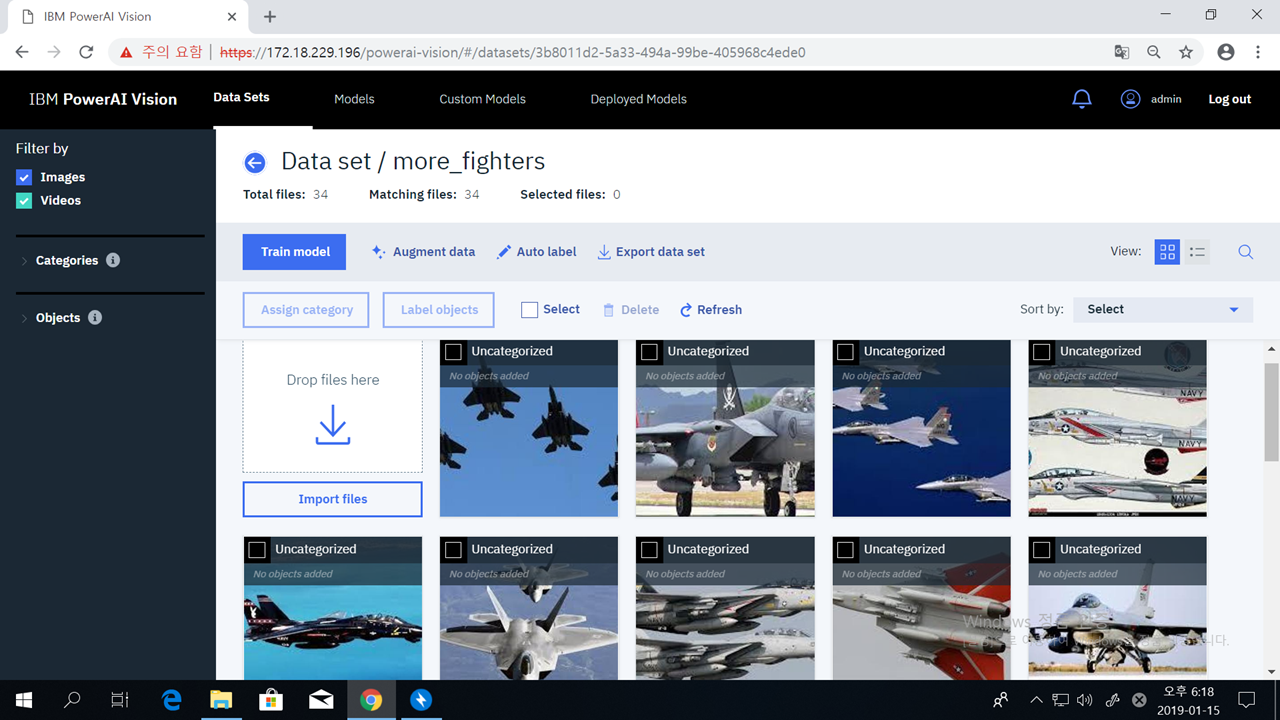
이제 메뉴 바 중의 'Auto label'을 클릭합니다. 그러면 아래와 같이 기존 deployed model 중에서 auto label에 사용할 model을 선택하게 되어 있습니다. 우리는 아까 만들어두었던 fighter_model1_deployed를 선택합니다.

이어서 'Auto label' 사각버튼을 누르면 auto label이 시작됩니다.

사진이 34장 밖에 안 되므로 auto label도 순식간에 끝납니다. 그러나, 기억하시다시피 우리가 사용한 'fighter_model1_deployed' model은 정확도가 별로 높지 않았습니다. 그래서인지, 34장의 사진 중 고작 10개의 object만 label했습니다.

그나마 아래와 같이 F14에 F16이라는 label을 붙여놓았습니다.

원래 어떤 model이라도 100% 정확할 수는 없으며, 따라서 auto label된 dataset은 결국 사람이 눈으로 검토하고 잘못된 label은 손으로 수정해야 합니다. 이제 위의 잘못 label된 것을 수정하겠습니다. 해당 사진을 클릭하면 아래와 같이 pop up 되는데, 여기서 나온 'Label objects' 사각버튼을 클릭합니다.

사진 오른쪽 위에 f16(1) X 라는 표시가 보입니다. 그 X 표시에 클릭하면 f16이라는 사각형으로 둘러싸인 label이 삭제됩니다.

이제 사진 오른쪽 위에 있는 f14(0) 이라는 표시를 선택한 뒤, 마우스를 전투기 사진 옆에서 click & drag 하여 사각형을 그려주면 이 전투기가 f14로 label됩니다.

이제 위쪽의 하얀 사각버튼 'Done editing'을 클릭하면 label 수정이 완료됩니다.

기존에 없던 object label을 이 메뉴에서 새로 추가하는 것도 가능합니다. 가령 아래 사진에는 F15와 F16 외에도, 머스탱(P51D) 프로펠러 전투기와 F22 스텔스 전투기도 보입니다. 이것들에 대해서는 아래와 같이 사진 오른쪽 위의 '+ Add New'를 클릭하여 즉석에서 새로운 label을 입력해주면 됩니다.




PowerAI Vision의 좀더 자세한 정식 manual은 아래 URL을 참조하세요.
https://www.ibm.com/support/knowledgecenter/en/SSRU69_1.1.2/navigation/welcome.html
